CNN 与图像识别
在上一篇教程 (使用Keras搭建第一个深度学习网络) 中,我们简单介绍了 Keras 框架,并且搭建了一个多层感知器模型来识别手写数字,达到了91%左右的正确率。不过在上一篇文末也说,如果我们改成使用卷积神经网络,那么识别手写数字的正确率得到很大的提升。不过什么是卷积神经网络,它为什么能够在这样的图像识别问题中取得如此大的突破呢?
1. 什么是卷积神经网络?
卷积神经网络 (Convolutional Neural Networks, CNN) 的灵感来源于“滤波器”在图像处理中的应用。它依靠一个卷积核在图像上滑动来 获取图像的特征 ,卷积核会对它范围内的像素进行一定的运算,并将它保存在一个新的像素中。而与之前的多层感知器不同,卷积神经网络可以保留高维空间的结构,因此常用于图像领域。并且能够保持更少的参数,大大减少了网络参数的数量。
不同于多层感知器模型,一个卷积神经网络中有许多功能不同的网络层。接下来,我将会逐一介绍每一层的原理和作用,以及我们应该如何在 Keras 中使用它。
1.1 Conv2D - 卷积层
卷积层是卷积神经网络中最基本的单位。每一个卷积层都包含一个卷积核 (由许多个滤波器组成) ,它会在图像上滑动,从而获得不同的特征。下图就展示了 一个 3x3 的滤波器在一张图像上的卷积过程:
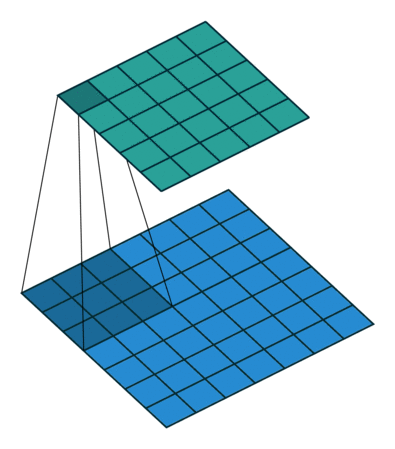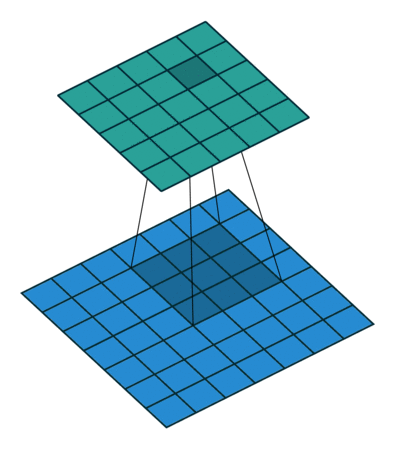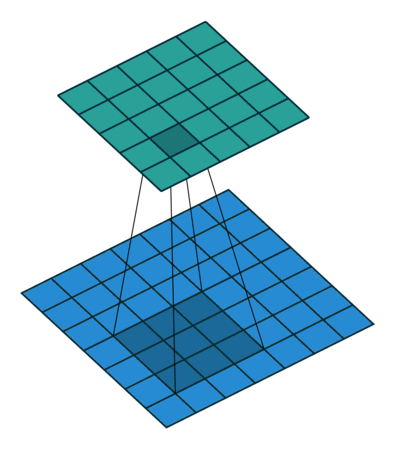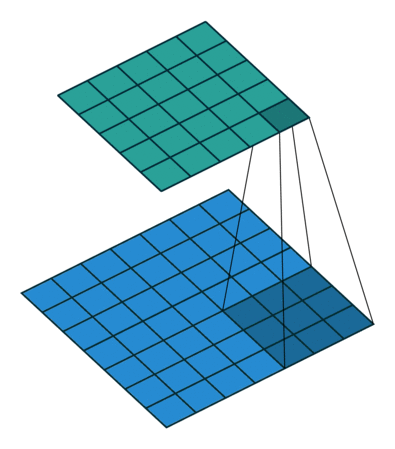
可以看到, 3x3 的滤波器会将原图像 (下方) 中每一个 3x3 的区域进行运算,并将结果赋值给新的图像 (上方) 。这样我们就实现了对图像的一次处理。而一个卷积层包含了很多不同的滤波器,从而将原图像处理为许多种不同的新图像:
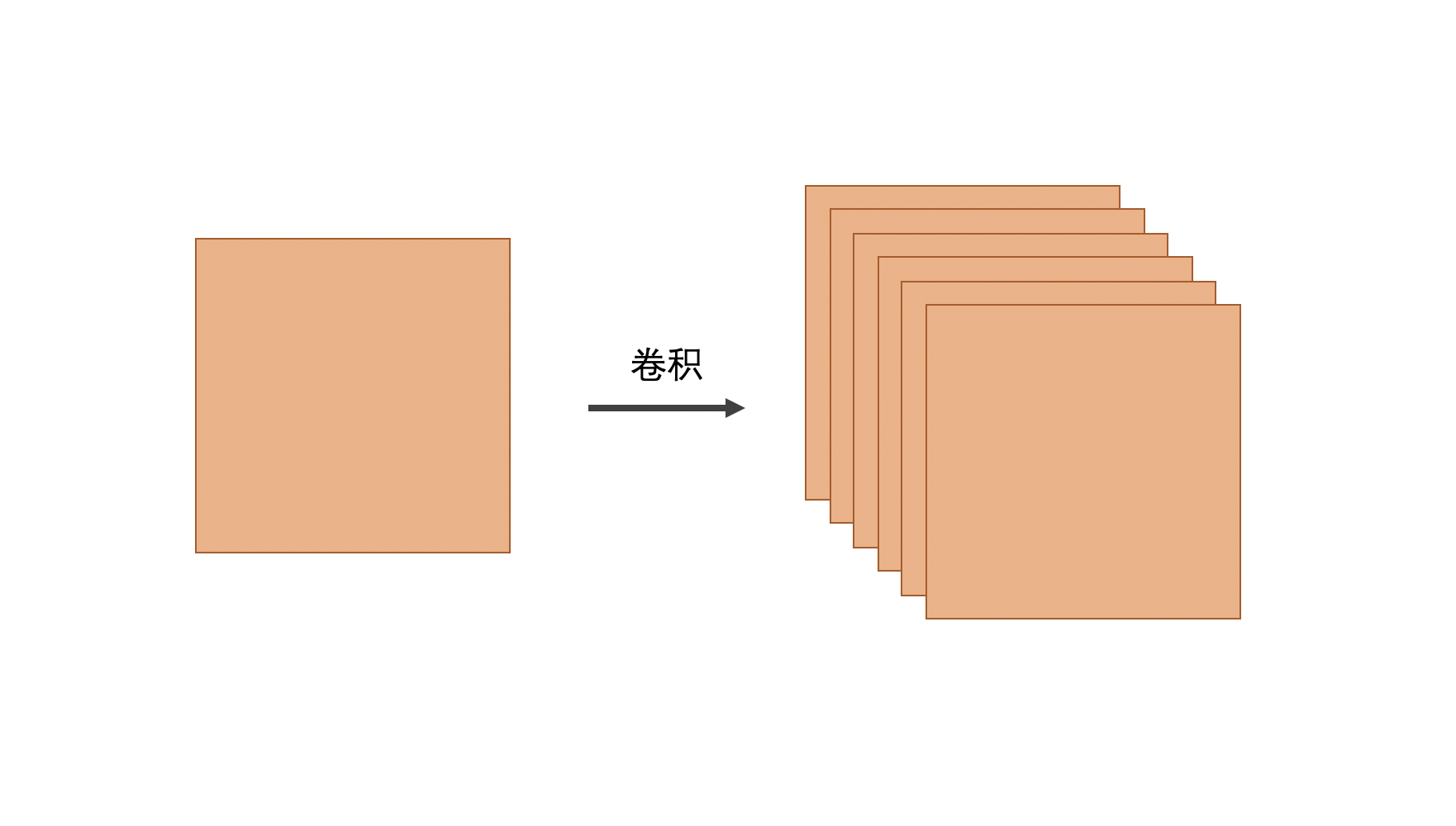
而在 Keras 中, keras.layers.Conv2D 就代表了一个卷积层,而其中包含了以下的参数:
-
input_shape 如果卷积层为模型的 第一层 ,则需要定义输入的大小。
-
filters 卷积核中包含的滤波器的个数。如果设置了12个滤波器,则最后会生成一个深度为12的图像。
-
kernel_size 设置卷积核的大小,其中可以设置一个整数 (代表了宽高都一致) ,也可以设置为一个二元整数元组。
-
padding 设置边缘填充的模式,其中包括
valid(不做填充) ,和same(保持图像大小不变) 两种模式。如果不做填充的话,图像会越变越小 (例如上方的动图,输出图片的宽和高都少了 2 ) 。 -
activation 设置当前层的激活函数
1.2 MaxPooling2D - 最大池化层
通过卷积层,我们就可以将原图像中的不同特征提取出来。但是卷积层会将图像的深度变得越来越大,这样无疑会让整个网络变得越来越大。所以为了保证网络的运行速度,除了卷积操作之外,我们还需要使用池化层 (Pooling) 来将图像压缩。而池化的操作有两种,分别为 平均池化 (AveragePooling) 和 最大池化 (MaxPooling) 。而通过实践证明: 最大池化的效果一般比平均池化的效果好 ,所以在这篇教程中,我们就只介绍最大池化层。
池化操作是如何进行的呢?下图就直观的展现了一个 2x2 最大池化的过程。我们将原图像划分成若干个 2x2 的小区域,然后取每一块区域中的最大值,然后将其组合生成一个新的图像。这样,通过 2x2 的池化,我们就将原图像的大小缩小为了原来的 1/4 。
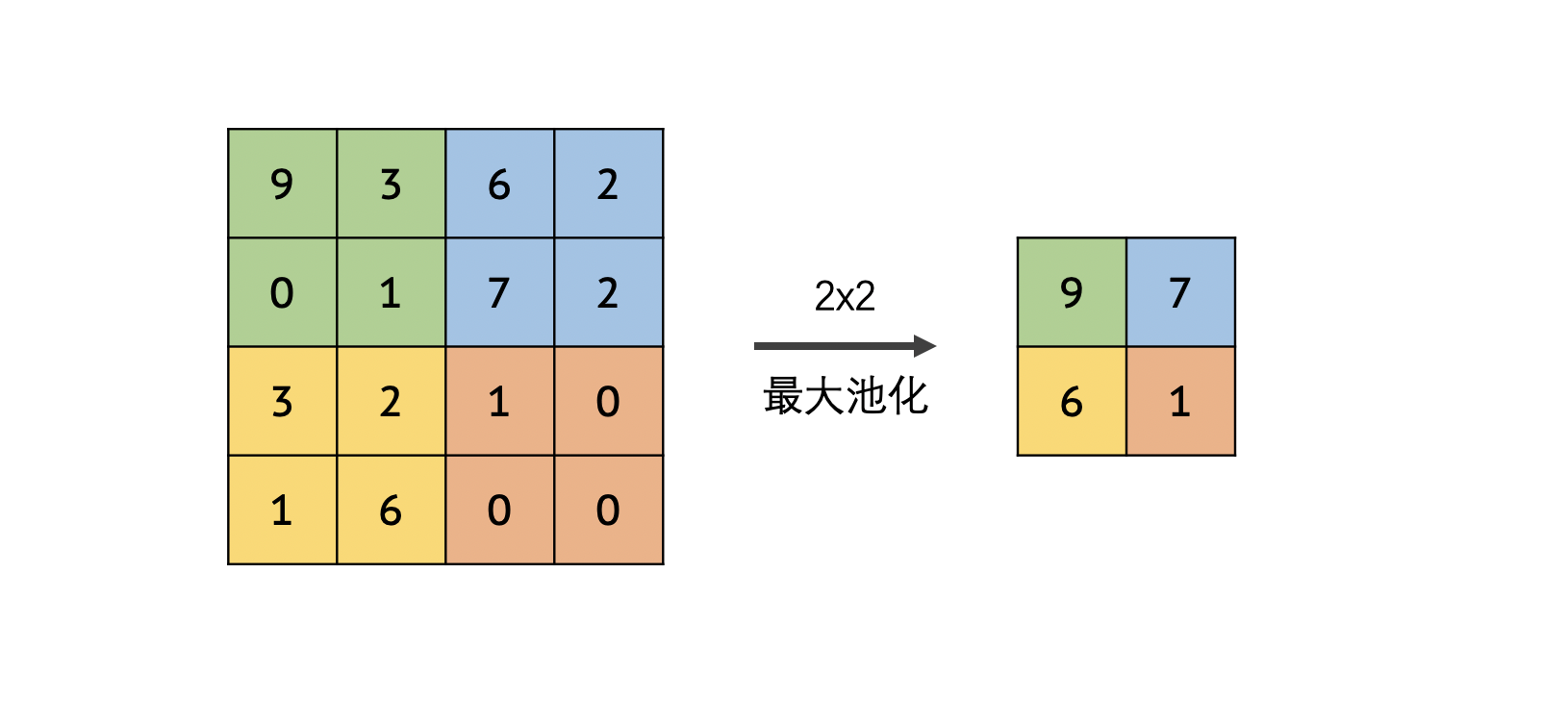
了解完了池化的原理之后,接下来让我们看一下如何在 Keras 中使用池化层。
Keras 中的最大池化层为 keras.layers.MaxPooling2D ,一般我们只使用一个参数:
- pool_size 设置池化的大小,可以设置一个整数 (代表了宽高都一致) ,也可以设置为一个二元整数元组。
2. Dropout 层与过拟合
在计算机视觉这一块领域中,深度学习网络非常容易出现过拟合 (Overfitting) 的问题。但是过拟合这是一个术语,我们应该如何理解它呢?
深度学习网络之所以能够根据输入进行分类,是因为它找到了输入与输出之间的关系。而如果我们的样本量较小,那么就容易出现模型 “记忆” 了样本库中图片的情况。此时,这个模型在训练集中的表现会非常好,但是在验证集中,模型的准确度甚至会下降,因为它的适应性更弱。这同时也说明了设置验证集的重要性。
那么,我们如何能够防止模型进行“记忆”,从而防止其进行过拟合呢?这个时候我们就需要使用正则化 (Regularization) 的方法。而 Dropout 便是一种非常有效的正则化方法。
Dropout 的原理是,在每一次训练时, Dropout 层会将两层之间的连接进行随机丢弃,丢弃的比例就由 rate 控制。下图就表示了一个 Dropout 的过程:
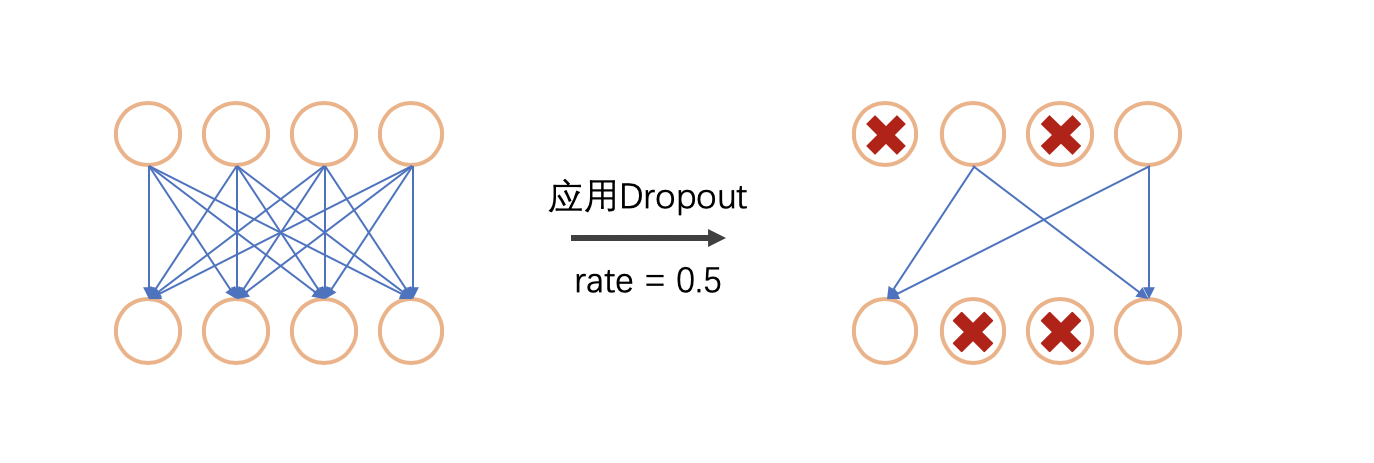
通过 Dropout ,我们能够防止网络中某些参数出现权重过大的情况,并且能够有效地防止过拟合。
而在 Keras 中,使用 Keras.layers.Dropout 就可以在两层之间添加 Dropout 层了。与上方的原理相似,一般来说你只需要设定一个参数:
- rate 随机丢弃的比例
3. 一个常见的卷积神经网络
了解了卷积神经网络的各个层,并且学习了 Dropout 层之后,我们应该如何将这一些层组合起来,组建一个卷积神经网络呢?
首先,一般卷积层的深度 (由 filters 参数控制) 应该要越来越大,并且在每一个卷积层后加上池化层。卷积之后,我们将其展平,并使用全连接层来将特征进行分类。和上一篇教程一样,最终我们将用一层 10 个元素的全连接层来输出概率。因此,下图就是一个可行的模型:
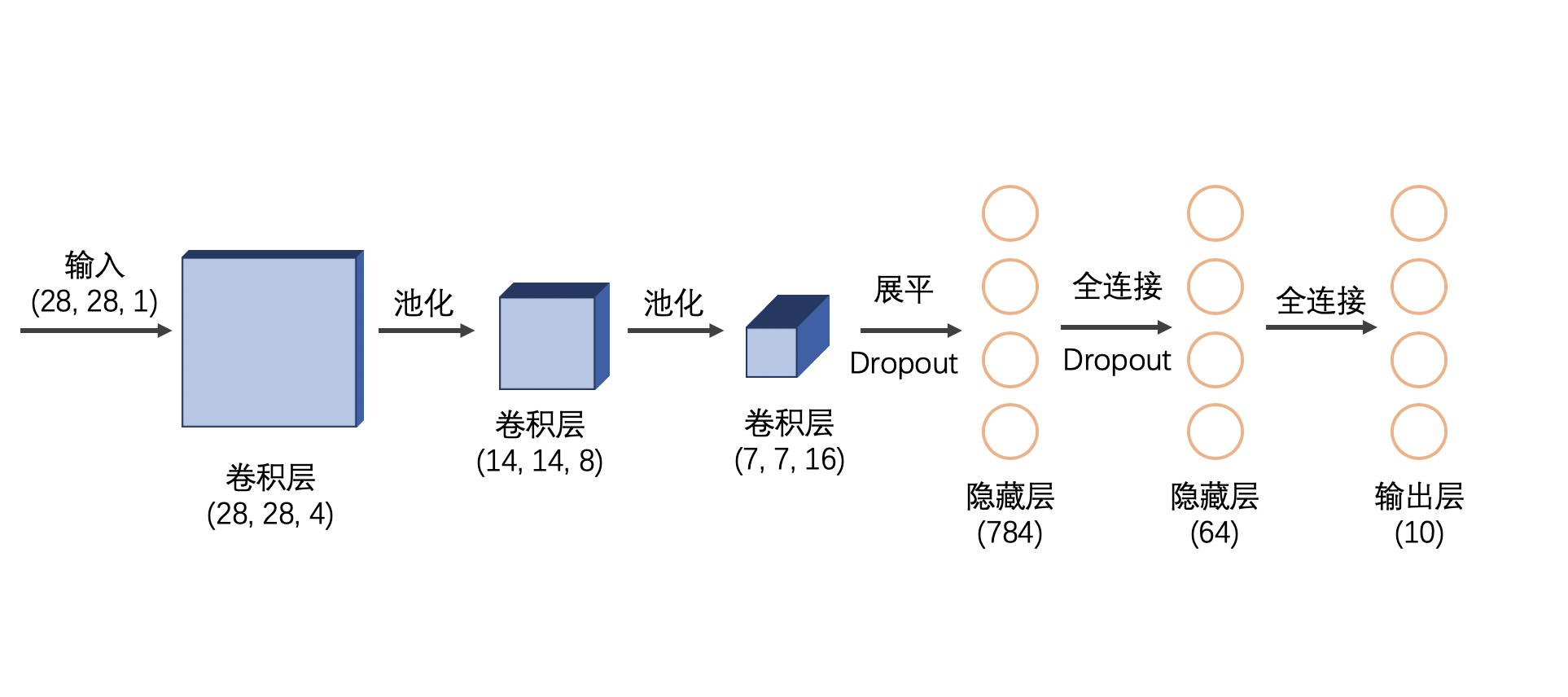
4. 编写代码,并运行模型
根据上面设计的模型,我们就可以编写代码了。不过要注意的是,对 X_train 的预处理方法有一定的不同,我们将其 reshape 为了 (60000, 28, 28, 1) 的大小。这是因为卷积神经网络传入的是图像,而最后一个代表了通道数。因为我们的数据都是灰度图,所以我们将通道数设为 1 ,这样才能够顺利传入网络。因此,我们得到了如下的代码:
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Flatten, MaxPooling2D, Dense, Conv2D, Dropout
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.astype('float32').reshape(-1, 28, 28, 1) / 127.5 - 1
y_train = to_categorical(y_train)
model = Sequential([
Conv2D(input_shape=(28, 28, 1),
filters=4,
kernel_size=3,
padding='same',
activation='relu'),
MaxPooling2D(2),
Conv2D(filters=8,
kernel_size=3,
padding='same',
activation='relu'),
MaxPooling2D(2),
Conv2D(filters=16,
kernel_size=3,
padding='same',
activation='relu'),
# (7, 7, 16)
Flatten(),
Dropout(0.25),
Dense(units=784,
activation='relu'),
Dropout(0.25),
Dense(units=100,
activation='relu'),
Dense(units=10,
activation='softmax')
])
# 输出模型结构
print(model.summary())
# 编译模型
model.compile(loss='mse',
optimizer='adam',
metrics=['acc'])
# 训练模型
model.fit(x=X_train,
y=y_train,
validation_split=0.2,
epochs=10,
verbose=2)
运行这一个程序,我们可以看到,模型在训练集和验证集中的准确率都达到了 98.5% 以上。这样的结果相较于前面的多层感知器模型已经有了非常大的提升。
Using TensorFlow backend.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 4) 40
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 4) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 8) 296
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 16) 1168
_________________________________________________________________
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 784) 0
_________________________________________________________________
dense_1 (Dense) (None, 784) 615440
_________________________________________________________________
dropout_2 (Dropout) (None, 784) 0
_________________________________________________________________
dense_2 (Dense) (None, 100) 78500
_________________________________________________________________
dense_3 (Dense) (None, 10) 1010
=================================================================
Total params: 696,454
Trainable params: 696,454
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 12s - loss: 0.0106 - acc: 0.9280 - val_loss: 0.0056 - val_acc: 0.9628
Epoch 2/10
- 8s - loss: 0.0051 - acc: 0.9674 - val_loss: 0.0037 - val_acc: 0.9756
Epoch 3/10
- 9s - loss: 0.0041 - acc: 0.9739 - val_loss: 0.0031 - val_acc: 0.9808
Epoch 4/10
- 8s - loss: 0.0034 - acc: 0.9780 - val_loss: 0.0029 - val_acc: 0.9812
Epoch 5/10
- 8s - loss: 0.0032 - acc: 0.9801 - val_loss: 0.0024 - val_acc: 0.9848
Epoch 6/10
- 8s - loss: 0.0028 - acc: 0.9824 - val_loss: 0.0024 - val_acc: 0.9840
Epoch 7/10
- 9s - loss: 0.0028 - acc: 0.9827 - val_loss: 0.0026 - val_acc: 0.9843
Epoch 8/10
- 8s - loss: 0.0026 - acc: 0.9837 - val_loss: 0.0028 - val_acc: 0.9831
Epoch 9/10
- 8s - loss: 0.0025 - acc: 0.9845 - val_loss: 0.0025 - val_acc: 0.9854
Epoch 10/10
- 8s - loss: 0.0024 - acc: 0.9854 - val_loss: 0.0022 - val_acc: 0.9865
结语
在本篇教程中,我们介绍了卷积神经网络、过拟合与Dropout,并且将其运用于识别手写数字的问题中,并且取得了很大的突破。当然,这个模型也并不是最优的。通过不断调整模型的结构与参数,你也许可以得到一个准确率更高的模型。
关于卷积神经网络更深层次的原理,大家也可以再多了解一些。 Keras 隐藏了许多网络中的技术细节,而深入地了解它们有利于你理解其中的原理。


